
Nvidia cherche à accélérer radicalement l'implémentation des modèles de grande envergure de l'IA générative, grâce à une nouvelle méthode de livraison des modèles pour une inférence rapide. Quels impacts cela pourrait-il engendrer sur la production d'application de l'IA en entreprise ? Les plates-formes d'entreprise sont assises sur une mine d'or de données qui peuvent être transformées en copilotes génératifs d'IA !
De toutes les annonces faite lors de la conférence GTC, une a retenue notre attention avec le lancement de la technologie logicielle Nvidia Inference Microservices (NIM). Ce logiciel représente une étape cruciale pour le développement générique de l’IA, conditionnant l’avenir de presque tous les développeurs de modèles et de plateformes de données. En 2024, les organisations se concentrent sur des déploiements de production à grande échelle, qui consistent à connecter des modèles d’IA à l’infrastructure d’entreprise existante, à optimiser la latence et le débit du système, à journaliser, surveiller et sécuriser, entre autres. Ce chemin vers la production est complexe et prend du temps, il nécessite des compétences spécialisées, des plateformes et des processus, en particulier à grande échelle.
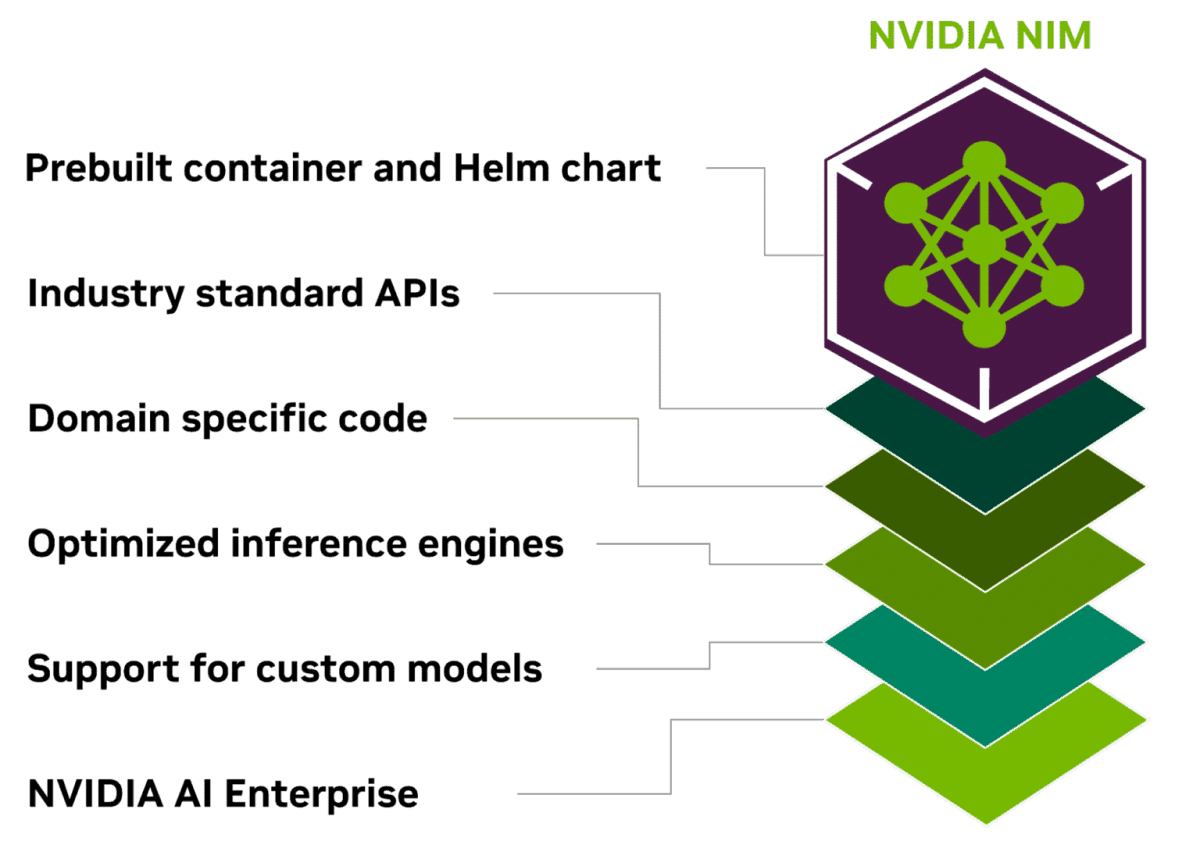
NIM est un ensemble de microservices cloud-natifs optimisés conçus pour raccourcir les délais de commercialisation et simplifier le déploiement de modèles d’IA génératifs partout, dans le cloud, les centres de données et les postes de travail accélérés par GPU. Les organisations vont pouvoir facilement créer et personnaliser des modèles de generativeIA pour accélérer la mise sur le marché de solutions et améliorer les applications d’entreprise avec des microservices.
Comment fonctionne NIM ?
NIM agit comme un container rempli de microservices. L’utilisation de conteneurs offre une grande flexibilité, permettant l’intégration de tout type de modèle, de modèles open source à ceux propriétaires, pouvant être exécutés sur tout GPU Nvidia, sur le cloud ou même un simple ordinateur portable. Le container NIM peut être déployé n’importe où, que ce soit dans un déploiement Kubernetes sur le cloud, un serveur Linux ou même un modèle sans serveur Function-as-a-Service.
Les développeurs peuvent accéder aux modèles d’IA via des API qui respectent les normes de l’industrie pour chaque domaine, ce qui simplifie le développement d’applications d’IA. Ces API sont compatibles avec les processus de déploiement standard au sein de l’écosystème, ce qui permet aux développeurs de mettre à jour leurs applications AI rapidement—, souvent avec seulement trois lignes de code
Une nouvelle approche, sans remplacement des modèles précédents
Pour autant, NIM ne remplace pas les précédentes méthodes de livraison de modèles par Nvidia. C’est une alternative qui inclut un modèle fortement optimisé pour les GPU Nvidia ainsi que les technologies nécessaires pour améliorer l’inférence.
NIM, une réponse efficace pour le déploiement RAG
L’un des principaux usages de NIM concerne le soutien des modèles de déploiement Retrieval Augmented Generation (RAG). Le VP de Nvidia pour l’informatique d’entreprise, Manuvir Das, insiste sur le fait que « la question est vraiment de savoir comment nous passons à la production ». L’espoir est de voir NIM apporter une réponse efficace à cette question.
Dans son ensemble, la technologie Nvidia NIM illustre l’importance de consolider et de faciliter le déploiement de l’IA dans différents environnements. User de cette alternative prometteuse permettra aux organisations d’accéder plus aisément aux bénéfices du déploiement RAG et de l’inférence, renforçant ainsi leur capacité à extraire de la valeur à partir de leurs données.