
Découvrez Moshi, l'IA de voix en temps réel qui transforme notre interaction avec les machines grâce à des conversations naturelles, émotionnelles et dynamiques.
L’intelligence artificielle vocale (IA vocale) est un domaine en plein essor qui révolutionne la façon dont nous interagissons avec les machines. Elle permet aux ordinateurs de comprendre et de répondre au langage parlé de manière naturelle et fluide, ouvrant ainsi un large éventail de possibilités.
Un nouveau pas dans l’intelligence artificielle vocale
Lors de l’événement en direct à Paris, le CEO de kyutai, Patrick, a dévoilé leur dernière innovation : Moshi, une IA de voix en temps réel. Développé en seulement six mois avec l’aide de 1000 GPU fournis par Scaleway, Moshi promet de révolutionner notre manière de communiquer avec les machines. Contrairement aux assistants vocaux traditionnels qui souffrent de latences et de limitations d’émotions, Moshi intègre un modèle neural unique capable de comprendre et de répondre instantanément tout en préservant les nuances émotionnelles de la voix humaine.
L’utilisation de 1000 GPU peut entraîner une consommation électrique très élevée, dépassant les 3,5 millions de kWh par an par exemple pour les modèles les plus puissants comme le NVIDIA A100 (si ces GPU fonctionnent en continu 24 heures sur 24, 7 jours sur 7 ). Cela souligne l’importance de l’efficacité énergétique dans les projets d’IA et l’optimisation des ressources dans les centres de données. Pour ce qui est du coût, en prenant un coût moyen de l’électricité de 0,15 € par kWh : Coût annuel : 3 504 000 kWh * 0,15 € = 525 600 €.
Les avancées technologiques derrière Moshi
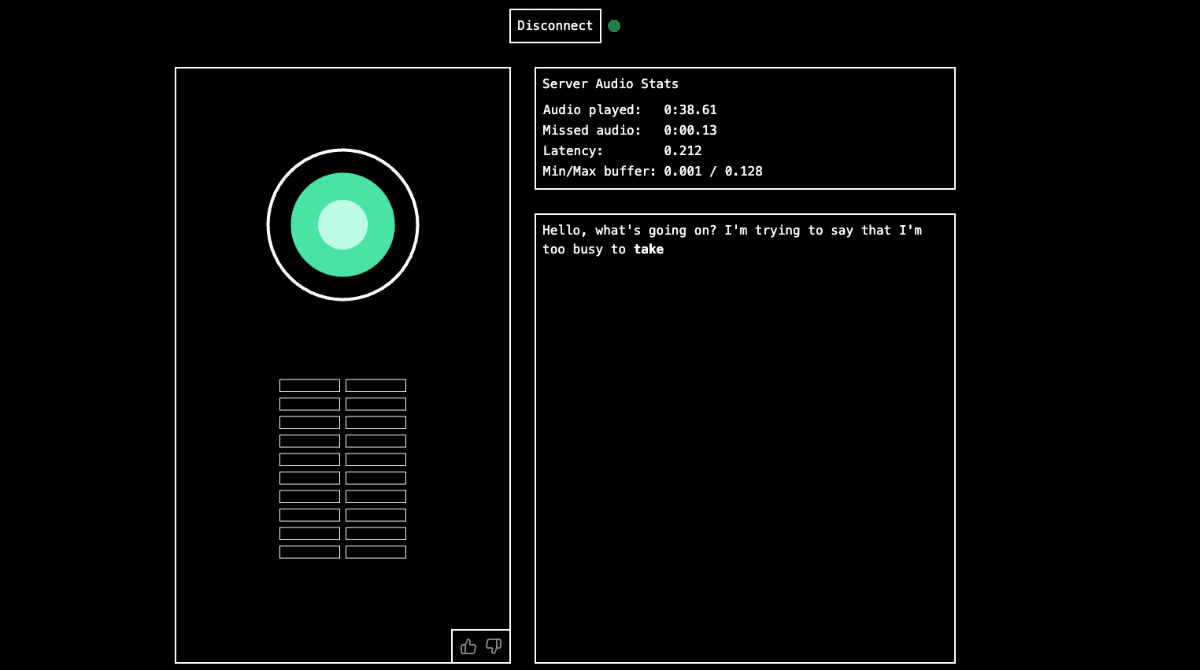
La grande avancée de Moshi réside dans sa capacité à intégrer de multiples flux de données vocaux, permettant des interactions continues et naturelles. Les assistants vocaux actuels, comme ceux de Siri ou Alexa, utilisent des pipelines complexes qui fragmentent le traitement vocal et induisent des latences de 3 à 5 secondes. Moshi, en revanche, combine toutes ces étapes en un seul modèle neural, réduisant ainsi la latence à 160 millisecondes.
Voici comment Moshi a été développé :
- Modèle de langue audio : Au lieu de se baser uniquement sur le texte, Moshi utilise des segments audio compressés pour entraîner un modèle de langue audio, capturant ainsi les émotions et les nuances de la voix.
- Multimodalité : Moshi peut générer à la fois du texte et de l’audio simultanément, offrant des réponses plus précises et contextuelles.
- Compression et efficacité : Grâce à des techniques de compression avancées, Moshi peut fonctionner en temps réel sur un appareil local, comme un ordinateur portable, sans nécessiter de connexion internet.
Applications et perspectives futures
La flexibilité de Moshi permet de nombreuses applications, notamment dans les domaines de l’accessibilité pour les personnes handicapées. En réduisant la barrière de la communication avec les machines, il ouvre la voie à des interactions plus humaines et inclusives. Avec Moshi, kyutai marque un NOUVEAU tournant décisif dans le domaine de l’intelligence artificielle vocale. La capacité de l’IA à comprendre et à reproduire les subtilités de la conversation humaine en temps réel promet de transformer notre interaction quotidienne avec la technologie. Les implications de cette avancée sont vastes, touchant des secteurs allant de l’assistance personnelle à l’éducation et à la santé. En tant que journaliste technologique, je suis convaincu que Moshi représente un pas de géant vers des machines véritablement communicatives et empathiques.